Local AI in the enterprise
"The 500k engineer better be spending 250k a year in inference tokens" - Jensen Huang, CEO, NVIDIA
There's a hell of a lot to unpack here.
I wrote Local LLM economics to challenge an intuition based in philosophy and feeling: local AI in the enterprise would never take off because the state of the art is all that matters.
This intuition comes from the race that we are in. The race to create more intelligent, more autonomous, and more capable LLMs. And the race for us developing the harnesses and tools to take better advantage of them and deploy them more widely.
A key insight from that research effort is:

The question then is:
How much worse than Opus-4.6 are the leading open source models today? What about in a year? What about in 3 years?
If the answer is vanishingly small, then tech executives looking at the above graph should start to wonder about their enterprise contracts with anthropic, cursor, openAI, etc.. And they should definitely renogotiate.
Any decently competent security team at a company is asking a difficult question of their inference providers: how do I ensure that 1. my data isn't being used to train future versions of the model, and 2. my data isn't being exfilitrated?
Run a model and its harness locally and the above questions don't need to be asked.
Let's say you get past those questions. Why think about using an open source model when claude can cook?
I thought I would always be willing to pay for access to the best advice/tools possible. The SOTA is all that matters. As long as it doesn't cost my salary to get access to it, any price would do.
I was wrong.
About 3 weeks ago Anthropic + Cursor started tightening the screws on billing. A typical enterprise pattern is each seat gets 500-1000 requests + $X in additional PAYG billing. Overnight, every call to Opus-4.6 + Codex-5.3 used 2+ requests. There was even a day where some of my colleauges used 47 requests on one call. It was insanity. People blew their budgets for the month in 3 hours.
At that time, only composer-1.5 was available at reasonable usage rates. Composer-1.5 is fine, but from anecdotal experience, was at a maximum useful for coding tasks that take up to 5 minutes. My colleagues were asking to pay for their inference spend themselves to get unblocked - they now had a baseline expectation of their productivity from the rosier cheap Opus-4.6 days and were not willing to go back to the dark ages.
Once composer-2.0 dropped, things changed. The gap between composer-2.0 and Opus-4.6 was much smaller. Composer-2.0 isn't anywhere near as intuitive as Opus-4.6 is in planning, but it works fine for execution. So: use Opus-4.6 for planning and Composer-2.0 for execution.
This has become my go-to.
My previous intuition was that only the SOTA mattered. Clearly, I'm compromising on that by using less than the SOTA for execution.
Blessed with some nice cold reality and better data, I have changed my mind! There is certainly a price I would pay for access to better models. More specifically, there is a price premium I am willing to pay for planning, which differs from the price premium I am willing to pay for execution.
Any tech company with an AI strategy should take a closer look at this. Developers were demanding the newest hardware for increased productivity and multi-tasking already. An additional $200 to upgrade from 24GB to 48GB and save on some thousands of AI spend.
Any harness/model router (Helicone, Vertex, etc..) will soon need a strategy for intelligently routing requests between the cloud and local inference. They will both need to understand the context of the request - general agent, planning, debugging - and what model the user expects the request to be routed to.
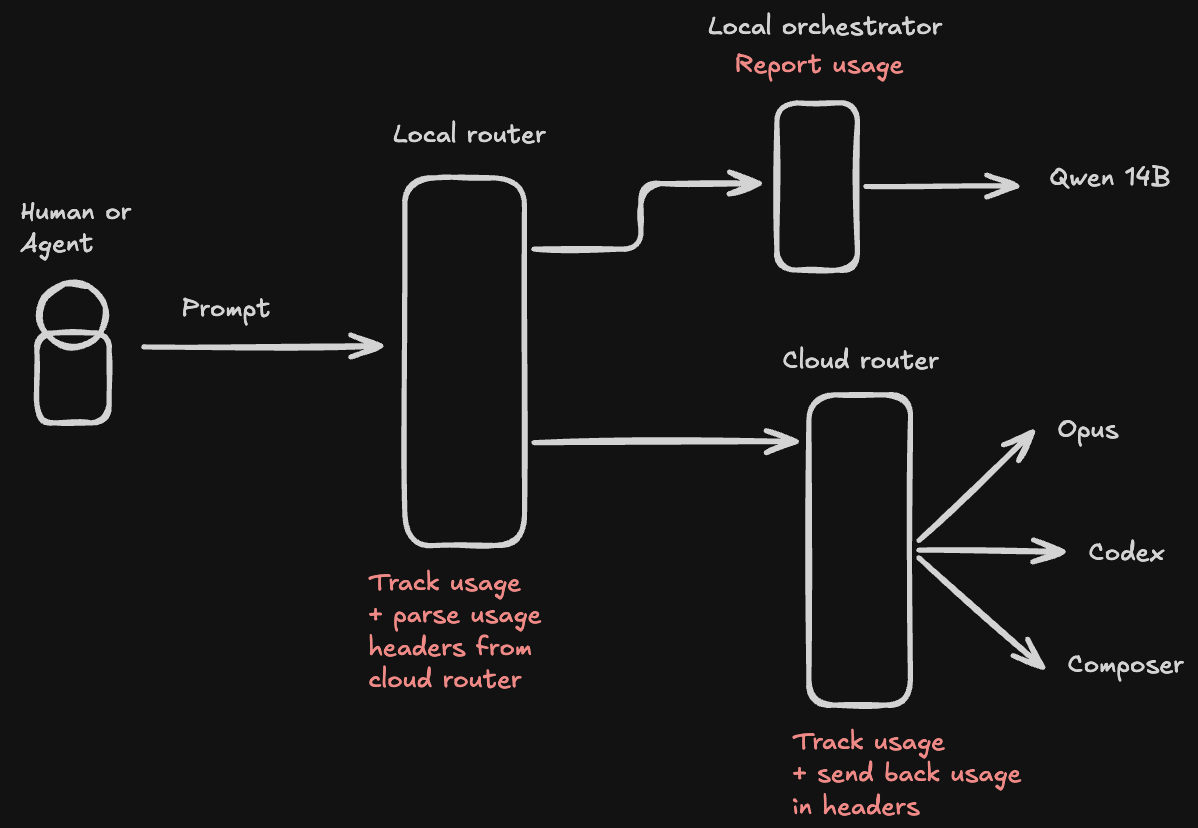
I, however, do not think that this will grow much beyond a model or two deployed locally.
Cloud has garnered broad adoption for a reason. Companies are willing to pay a premium for access to hardware if they can pay a variable rate based on usage rather than large step functions in capex for servers they won't get full utilization out of.
Running models is really no different, except in this case, the additional capex was already coming down the line. In that light, the premium of intelligence vs already earmarked capex is worth a close look.