Model Context Protocol: Learning
Pre-premise
When I wrote this in August of 2025, claude skills had not yet been launched, and the sentiment around MCP was one of panic - everyone was rushing to implement their own MCP servers. Poorly secured servers lead to exploits. The hype around MCP at this point has died down, but the focus on making agents useful is as ferverent as ever.
Premise
The Model Context Protocol, by Anthropic, is a model-agnostic protocol for managing context.
I like to think of reasoning models as a probabilistic word generator. Ask Sonnet or GPT-4 about [insert general query] and it's statistically likely you'll get a solid answer.
Take that same reasoning model, and ask it to write another page of your web app, and you likely won't get what you wanted. It's lacking context. You'll increase your odds of getting a good result if you provide code examples from your current code, screenshots of your preferred designs, etc..
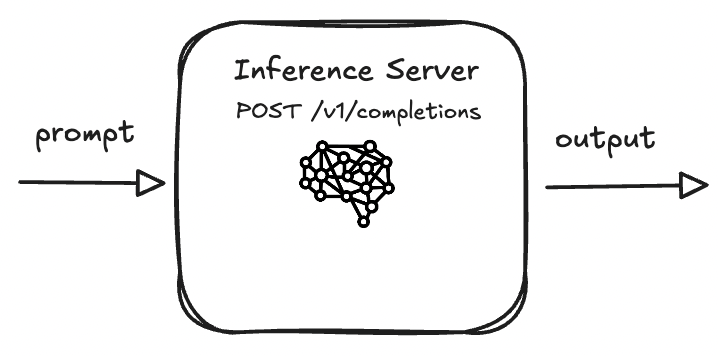
Recall that as of today, all inference servers accept is a prompt. i.e.
POST /v1/completions {prompt: "write me a sentence"}
Context is additional words in a prompt. Essentially, words. As of writing this article, the majority of models can accept 128k tokens in context, or about 100k words.
There's one main issue with doing this. Copy + pasting is time consuming, and with certain sources, not feasible. If you don't believe me, try to get chatgpt to analyze all eth transactions to a set of wallet addresses.
WWYD?
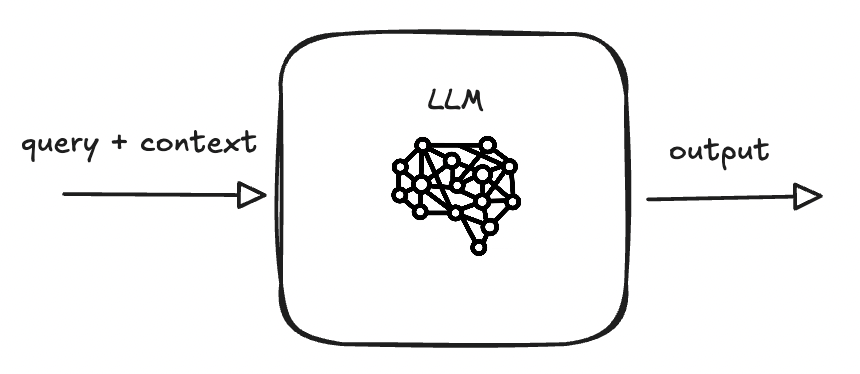
There has to be a better way to do this. Maybe a common interface that inference server consumers could call to programatically access context on a particular thing.
At a high level, we would want to enable something like:
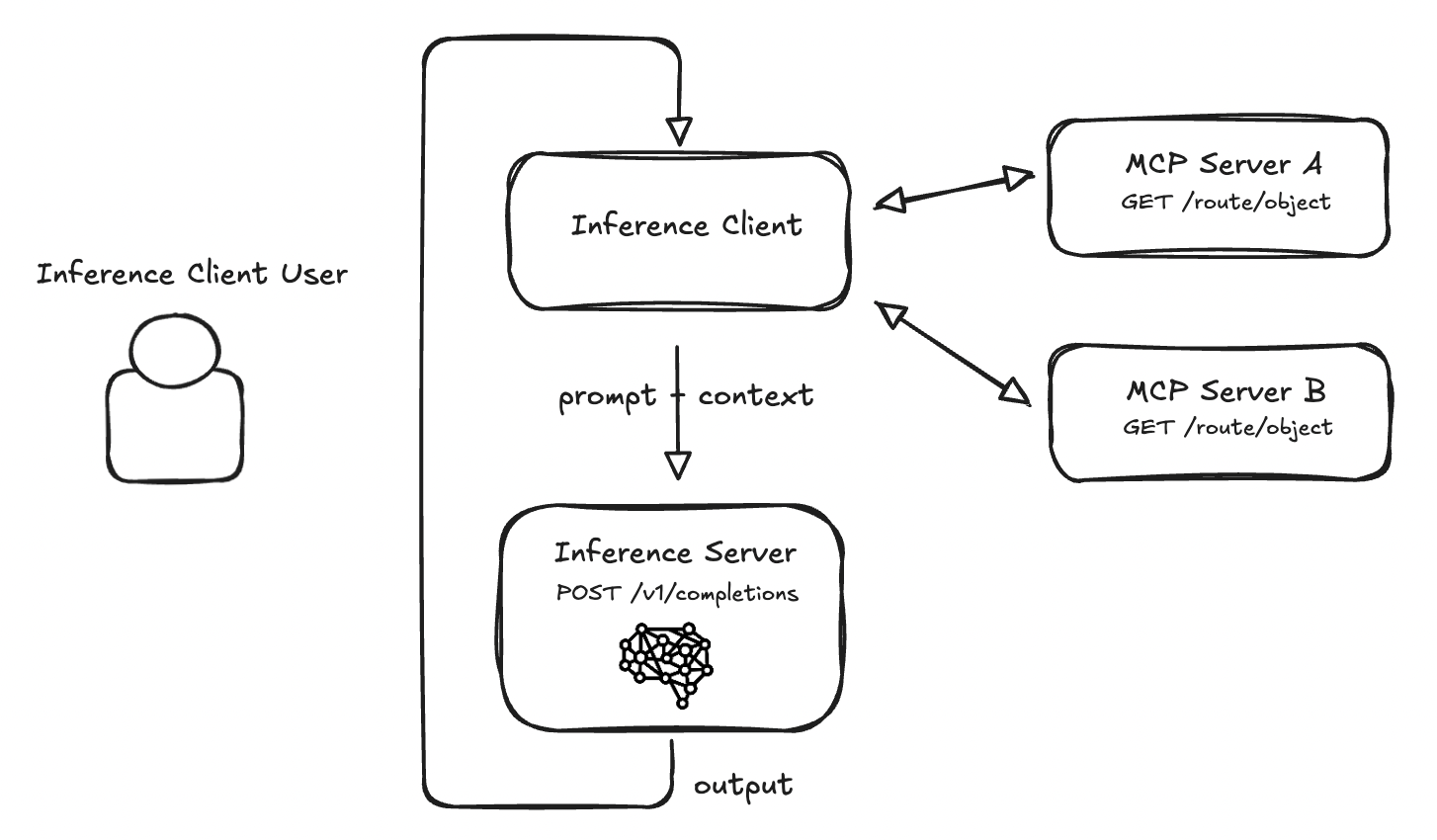
So: we want clients to be able to ask a server for context.
Wrt to context clients, we have a few requirements:
- Expected schema: none
- Generally when engineers/hackers ask for data we always look at the structure of the data. With context there currently is no structure. We'll explore that in a future blog post.
- Model ID + Model version
- Clients can work with multiple models in a single workflow. Or, a created workflow may update the internally pinned models it uses.
Wrt to context servers, we have a few requirements:
- accept model ID + version (good context differs based on the model)
- multitenant (Figma can serve context for you and for me)
- scoped to resource(s) (Figma probably shouldn't send context about your mobile app flow and TV OS flow at the same time)
- AuthN/AuthZ
- OTEL trace propagation for o11y (a good inference server offering could own multiple mcp servers)
- A docs endpoint to describe the intent of the context the server will return
i.e. if we asked a server for context, this proto definition would be a good place to start:
msg LLMContextRequest {
modelID string
modelVersion string
}
msg LLMContextResponse {
context string
}
And, how should servers handle their internal routes? Does it make sense for a service with established APIs and access patterns to spin up a new context server and essentially swap context in for whatever resource is there currently?
i.e. take maps.googleapis.com/maps/api/place/details/ - should they have a maps.googleapis.com/maps/api/context/place/details/?
Since context is just plain text, why even create a separate server? Why not just have your inference server client call directly to the API that has the resource data you're interested in and serve that directly to the model?
Ok, so are APIs enough? Does that mean MCP isn't all that useful?
We want to connect inference with data from the outside world. Luckily, as software has eaten a good portion of the world, we have already developed a whole ecosystem around serving data with reliability. Some engineers spend their whole career doing API design!
That data needs to be serialized and deserialized by clients, so its reasonable to expect we could give inference clients the same tools. Models could either invoke curl or grpcurl commands directly from a terminal, or write code to be executed in a WASM sandbox that outputs the desired data to stdout.
There's a few problems:
- This assumes that models are just as good at dealing with context in plaintext as they are in json/protobuf/please god not xml/whatever cursed object notation you use.
A 2024 paper finds there is widespread inconsistency in model performance based on prompt formatting: Does Prompt Formatting Have Any Impact on LLM Performance? . One benchmark is about domain specific knowledge in finance, the other 6 are relevant and cover entity extraction, code generation and translation, and general reasoning.
Prompt design screenshot from the above paper on ArXiv:
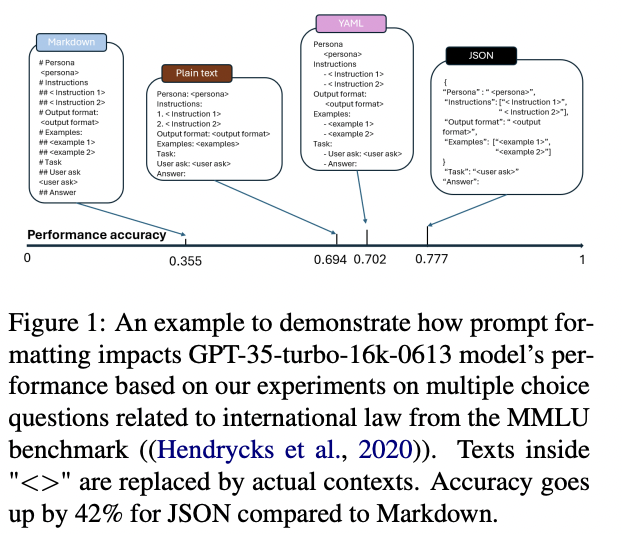
There are clearly inconsistencies, so we can't assume all prompt inputs are created equally.
-
This also assumes that given a full API server, that a model will be strong at finding exactly which endpoint it needs, and predicting usage of that endpoint without docs or examples. This isn't true. Models are anecdotally poor at performing under too little context, and anecdotally poor at performing under too much context. All API providers could add an additional
.../docs/endpoint to each of their APIs that provides usage examples. -
API endpoints aren't deterministically discoverable. A model could use something like
grpcurl listto find what endpoints are available, but this is adding non-determinism, and the model could decide its too much work and instead decide mocking it is acceptable for your use case.
Discoverability
While many LLMs could be able to predict what APIs to call for a specific task (i.e. "what % of images in my ecr repos are AMD vs ARM?"), we can improve performance by giving them instructions on the APIs and what they are about.
I want to call out that "improve performance" is important here and not something for eyes to glaze over. We're still in the early days of building workflows with these non-deterministic reasoners; eeking out additional performance could be the difference between a workflow being viable for the enterprise vs not.
LLMs do well on instructions, not all servers have an endpoint that will tell an inference server what resources are available at that server.
Tooling
Function calling appeared in mid-2023 in commercial APIs. Through a lot of extra work on the model side that I don't yet understand, they were able to get models to somewhat reliably emit json and adhere to schemas:
{ "tool_name": "run_command", "arguments": { "cmd": "grpcurl", "args": ["-plaintext", "..."] } }
This is impressive because models are verbose, and the model is adhering to a schema that didn't yet exist in much of its general training data.
A model will perform better at tool calling if we give it a list of the tools it can call.
An important piece here is security - models are not-deterministic and while it may not happen every time a query is executed, its possible that a model will predict the best way to solve your particular challenge is by:
{ "tool_name": "run_command", "arguments": { "cmd": "rm", "args": ["-r", "-f"] } }
your env files and start from scratch. It was all vibe-spaghetti anyways, right?
As with all software, there is maliciousness here as well. Anything that connects a reasoning agent to the outside world can be abused.
A model could be strongly enforced to ask you what tools it can call, but its better to lock it down on your orchestrator. And if you have private keys or other sensitive material stored on your local machine, it's worth a little bit of extra effort to further isolate it.
Back to protocol design
We have 3 types of things to present to a model orchestrator:
- context (in either plaintext or json)
- APIs to call (route name and examples)
- Tools to call (tool name, modifiers, and examples)
While these are things we know we need today, there may be other model primitives in the future. Keeping this in mind, representing those 3 things in a unified type will allow us to evolve the types without increasing the cardinality of named routes (i.e. ListTool, ListAPI, ListCapability)
Let's sketch this out in go:
type MCP interface {
Describe() ([]ResourceSummary, error)
GetResource(uri string) (ResourceDetail, error)
Invoke(uri string, opts []string) error
}
type ResourceSummary struct {
Type ResourceType
Name string
URI string
}
type ResourceDetail struct {
Type ResourceType
Name string
URI string
Usage []byte
}
type ResourceType int
const (
Context ResourceType = iota
API
Tool
)
Protocol: gRPC
We represent APIs, tools, and context as Resources. When first reaching out to a MCP server, the orchestrator can use Describe to fetch all ResourceSummary-ies the server has to offer. To get detailed information about a specific resource, the orchestrator can use GetResource with the resource's URI to fetch the full ResourceDetail, which can have arbitrary amounts of examples to guide the model's usage of the resource.
Since tools are wrapped experiences for models, we need a way to invoke them. Thus, the Invoke endpoint with the uri of a tool to do so.
For the transport layer, I propose grpc. It's battle tested, well adopted, and schema definitions in proto3 translate well to all languages i'm aware of.
The protocol
The above is what I would propose. How does Anthropic's MCP differ?
Anthropic's MCP Interface (distilled to Go)
type MCPServer interface {
// Tools
ListTools() ([]Tool, error)
CallTool(name string, arguments map[string]interface{}) (ToolResult, error)
// Resources
ListResources() ([]Resource, error)
GetResource(uri string) (ResourceContent, error)
// Prompts
ListPrompts() ([]Prompt, error)
GetPrompt(name string) (PromptContent, error)
}
type Tool struct {
Name string `json:"name"`
Description string `json:"description"`
InputSchema map[string]interface{} `json:"inputSchema"`
}
type Resource struct {
URI string `json:"uri"`
Name string `json:"name"`
Description string `json:"description"`
MimeType string `json:"mimeType"`
}
type Prompt struct {
Name string `json:"name"`
Description string `json:"description"`
Arguments []PromptArgument `json:"arguments"`
}
type PromptArgument struct {
Name string `json:"name"`
Description string `json:"description"`
Required bool `json:"required"`
}
Differences Between Approaches
-
Communication Protocol
- Mine: gRPC
- Anthropic's approach: JSON-RPC 2.0 over stdio/HTTP/WebSocket
-
Resource Management
- Mine: Two-tier system with
ResourceSummaryandResourceDetail. My "Resource" is a unified concept that can represent context, APIs, or tools with aResourceTypeenum. - Anthropic's approach: Single
Resourcetype for listing (contains metadata like URI, name, description, mimeType), separateResourceContentfor actual content. Anthropic's "Resource" is specifically data/content that can be read.
- Mine: Two-tier system with
-
Tool Support
- Mine: No explicit tool support in interface
- Anthropic's approach: Dedicated
ListTools()andCallTool()methods
-
Prompt Support
- Mine: No explicit prompt support in interface
- Anthropic's approach: Dedicated
ListPrompts()andGetPrompt()methods
-
Resource Identification
- Mine: Uses
URIfield - Anthropic's approach: Uses
URIfield (same)
- Mine: Uses
-
Resource Types
- Mine: Custom
ResourceTypeenum (Context, API, Tool) - Anthropic's approach: Uses
MimeTypestring field
- Mine: Custom
-
Method Granularity
- Mine: 3 methods (
Describe,GetResource,Invoke) - Anthropic's approach: 6 methods (tools, resources, prompts each have list/get variants)
- Mine: 3 methods (
Additional Differences:
- Naming: Anthropic Prompt = what I call Context. Anthropic Resource = what I reference as APIs.
Appendix
Whether or not a LLM will be "good" (I lack specific benchmarks to aspire to here) depends on the data it was trained on. Given these LLMs were trained by web crawlers, they should have a hefty amount of params that were tuned on both plaintext and json. Some models trained for code inference have tokens just for json, i.e. ": is a token in some models.
python3 -c "import tiktoken; enc=tiktoken.encoding_for_model('gpt-4'); txt='{ \"a\": 1, \"b\": 2 }'; ids=enc.encode(txt); print(ids); print([enc.decode([i]) for i in ids])"
[90, 330, 64, 794, 220, 16, 11, 330, 65, 794, 220, 17, 335]
['{', ' "', 'a', '":', ' ', '1', ',', ' "', 'b', '":', ' ', '2', ' }']